
XSS Stored
=
Unicode Normalization
+
User-Agent
Cross-Site Scripting (XSS) stands as one of the most well-known and widely exploited vulnerabilities in the history of bug bounty programs. For this reason, I believe it’s an opportune moment to refresh our approach when dealing with a field that is reflected on the client side.
While analyzing a website, which I’ll call victim.com, a platform that specializes in selling tickets for various sports and entertainment events, I observed an unusual behavior in how the application processed user input.
One strategy I employ when encountering a field that reflects its value is to test various inputs and compare the server’s responses, rather than launching a barrage of payloads that might quickly draw attention.
For illustrative purposes, I’ll use the double quote character ":
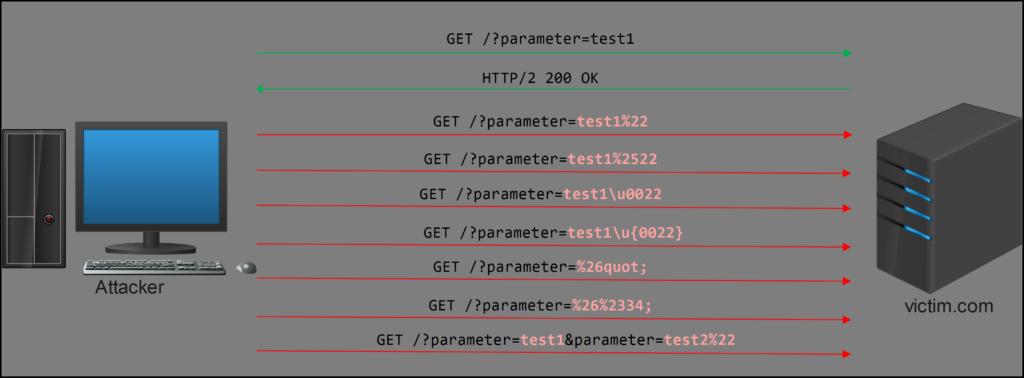
However, in this instance, I discovered that the application employs anti-XSS filters, along with monitoring measures to temporarily block (for 5 minutes) users upon detecting 3 requests deemed malicious, and to permanently block when more than 10 malicious requests are detected, rendering my previous testing methods entirely ineffective.

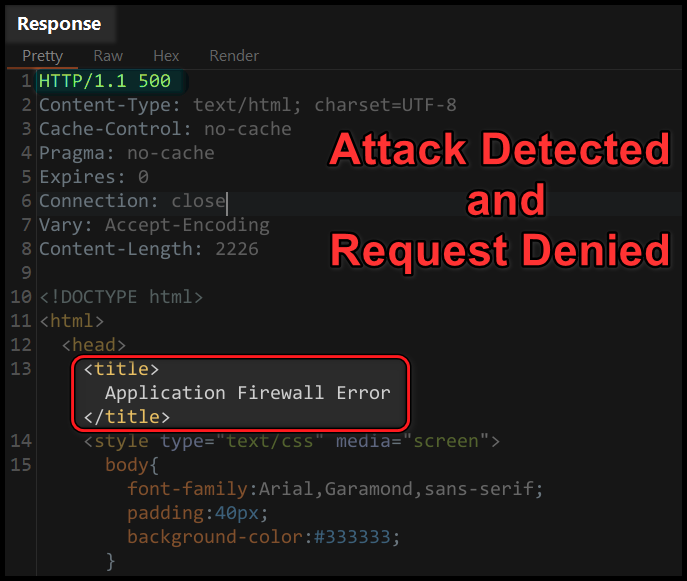
I decided to delve deeper into the application’s behavior, utilizing Unicode notation, fullwidth, halfwidth, normalization, and compatibility of special characters.
To quickly cover these concepts, let’s see them in a summarized form.
Unicode Notation
Unicode notation refers to the method by which Unicode characters are represented through a series of codes and symbols. These notations enable programmers and software designers to work with Unicode characters without relying on a visual representation of the character. Instead, various means of character representation are used, such as hexadecimal code sequences or character decoding.
Unicode notations include:
- Unicode Code Point Notation: This notation employs the prefix U followed by its hexadecimal code point. For example, the letter “G” can be represented as U+0047.
- Unicode Escape Notation: This notation uses the prefix \u followed by four hexadecimal digits to represent a Unicode code point. For example, the letter “G” can be represented as \u0047.
- Unicode Sequence Escape Notation: This notation uses the prefix \x followed by two hexadecimal digits to represent a Unicode character. For example, the letter “G” can be represented as \x47.
- Extended Unicode Escape Notation: This notation employs the prefix \U followed by eight hexadecimal digits to represent a Unicode code point. For example, the letter “G” can be represented as \U00000047.
In practice, backends working with Unicode should be capable of interpreting these notations, as they are part of the Unicode standard specification and are widely used in computer applications.
Fullwidth and Halfwidth
Width refers to the amount of horizontal space a character occupies in a line of text, or equivalently, the cell allocation in a display grid. The width of a character can be classified into two categories:
- Fullwidth.
- Halfwidth.
The reason for the existence of characters with two different widths in Unicode is due to the need to represent characters from different writing systems within a single character encoding. If all characters were represented with the same width, characters from Asian languages would appear too small and difficult to read, whereas characters from European and Middle Eastern languages would appear overly large:
| Character Representation | ||
|---|---|---|
| Full Width | Master | U+FF2D U+FF41 U+FF53 U+FF54 U+FF45 U+FF52 |
| Half Width | Master | U+004D U+0061 U+0073 U+0074 U+0065 U+0072 |
In addition to fullwidth and halfwidth characters, Unicode also includes:
- Combining Characters: These are used to create more complex characters by combining two or more simple characters.
- Control Characters: These are used to control how text is displayed in computer applications.
Below are two independent examples illustrating the combination and control of characters:
| Combining Characters | |
|---|---|
| Input Data | Unicode Representation |
| M̂äste͜ř | U+004D (M) + U+0302 (̂) + U+0061 (a) + U+0308 (̈) + U+0073 (s) + U+0074 (t) + U+0065 (e) + U+035C (͜) + U+0072 (r) + U+030C (̌) |
| Control Characters | |
| Input Data | Unicode Representation |
| M\x07a\x1bster | \u004D\u0007\u0061\u001B\u0073\u0074\u0065\u0072 |
Unicode Normalization
This is the process of standardizing the representation of Unicode characters to ensure they are equivalent in semantic content, regardless of their representation. Unicode normalization addresses the issue that a single character can be represented in multiple ways within Unicode. This can pose a problem in text comparison and search, as two character sequences that represent the same concept may not compare correctly.
This concept is based on the idea that there are multiple equivalent ways to represent a single Unicode character, but some of these ways may be preferable in certain contexts, depending on user and system needs. For example, the letter á can be represented either as a single character á or as the combination of an a and an acute accent ´, with both forms being equally valid and representing the same Unicode character.
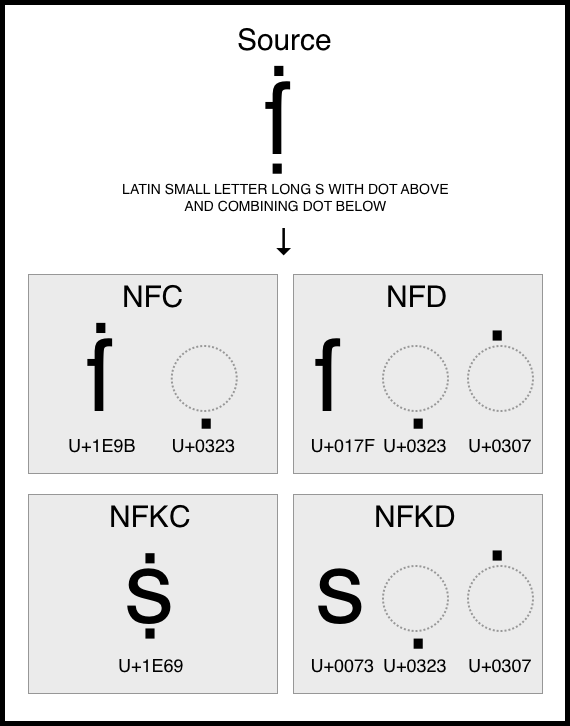
There are several forms of Unicode normalization, identified as NFC, NFD, NFKC, and NFKD, which differ in how transformations are performed.
- Canonical Normalization Form (NFC): Focuses on performing all necessary canonical decompositions for each character and then recomposing them into a canonical sequence. For instance, the sequence e plus an acute accent ´ is composed into the letter é(\u00E9). This form is recommended for storing text strings.
- Compatibility Normalization Form (NFKC): Similar to NFC, though it also replaces sequences of characters that are compatible in Unicode with unique characters. For example, the sequence 1/2 is converted into ½. This form is useful for text searches and comparisons.
- Decomposed Normalization Form (NFD): Focuses on decomposing characters into their most basic form, that is, each character that has an equivalent representation as a sequence of characters is decomposed into that sequence. For example, the letter é is decomposed into the sequence e plus an acute accent: \u0065\u0301. This form is often used for string comparison operations.
- Compatibility Decomposed Normalization Form (NFKD): Similar to NFD, but also applies the same idea of compatibility as NFKC. That is, it decomposes characters that are not compatible in Unicode. For example, the trademark symbol ™ is decomposed into TM. This form is useful for text searches and filtering.
Additionally, there are two more forms of Unicode normalization, “NFKC_Casefold” and “NFKD_Casefold,” but we won’t cover them this time.
Special Characters Compatibility
Unicode compatibility is a form of equivalence that ensures between characters or sequences of characters that may have different visual appearances or behaviors, the same abstract character is represented. For example, 𝕃 is normalized to L. This behavior could expose some applications with weak implementations that perform Unicode compatibility after the input has been sanitized.
This behavior in character interpretation is a perfect starting point to check which internal protections and/or WAFs allow the injection of special characters (both fullwidth and halfwidth) that have different code points and represent the same abstract content once normalized.
In the following comparative table, transformations and forms of representation for the less-than sign character < are observed:
| Table of Results and Final Representations | ||
|---|---|---|
| Character | Transformation | Result |
| < | URL Encoding | %3c |
| ﹤ | URL Encoding for similar character with different code point | %EF%B9%A4 |
| < | URL Encoding for similar character with different code point | %EF%BC%9C |
| ≮ | URL Encoding for similar character with different code point | %E2%89%AE |
| ﹤ | Double URL Encoding | %25EF%25B9%25A4 |
| < | Double URL Encoding | %25EF%25BC%259C |
| ≮ | Double URL Encoding | %25E2%2589%25AE |
You can read my research here. (Spanish)
Exploitation
Now, with a basic understanding of the theory behind notation, fullwidth and halfwidth, normalization, and Unicode compatibility, let’s proceed with testing against the victim application.
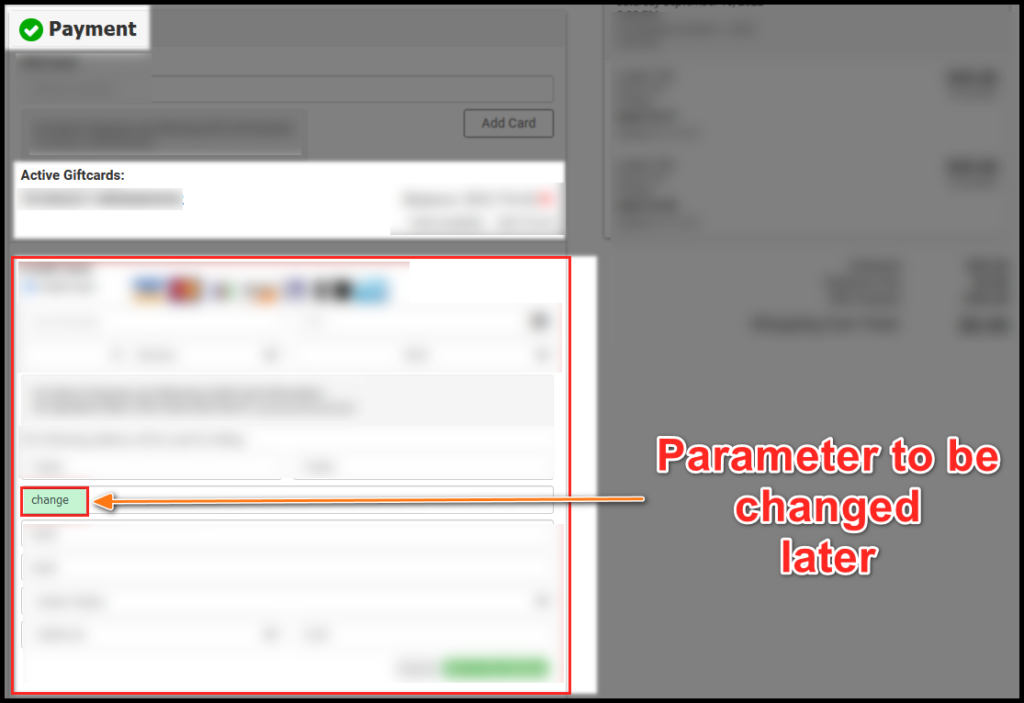
I log in with valid credentials and navigate to the section that contains the vulnerable parameter. I fill in the necessary information, inserting the value of “change” into this parameter:
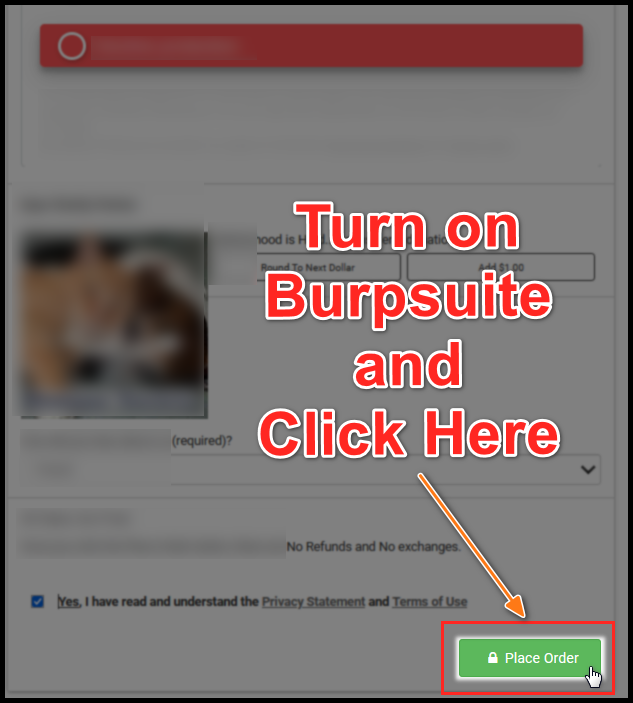
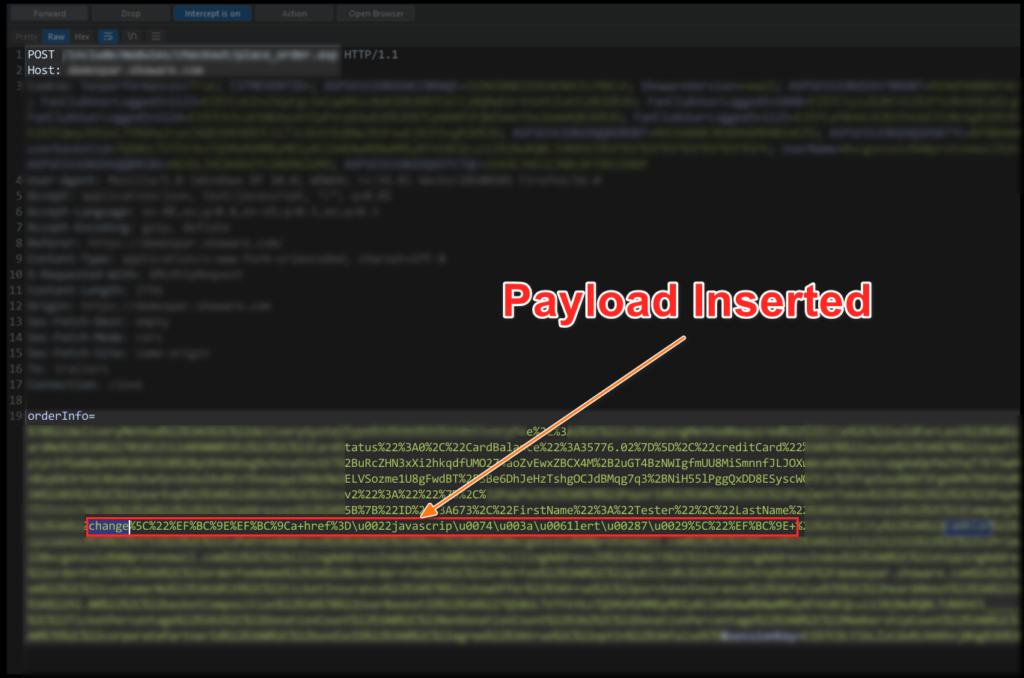
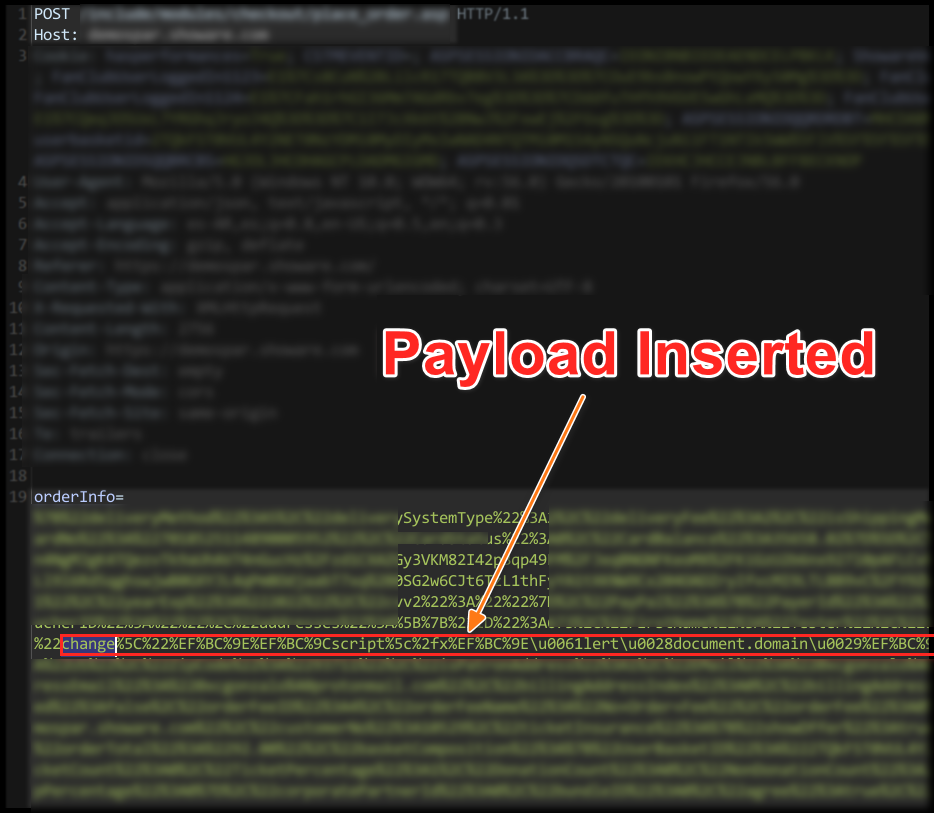
I intercept the request and see that the orderInfo parameter sends a URL-encoded JSON object. At this point, I look for where my value is reflected and add my payload, which utilizes representations of special characters as shown below:
change"><a href="javascript:alert(7)">
Here, the special characters encoded with UTF-8 and URL Encoding are < and>:
The rest is common UNICODE encoding:
After executing the request, the server does not recognize it as a malicious injection and allows the application’s normal flow to continue. It is verified that the purchase has been processed correctly:

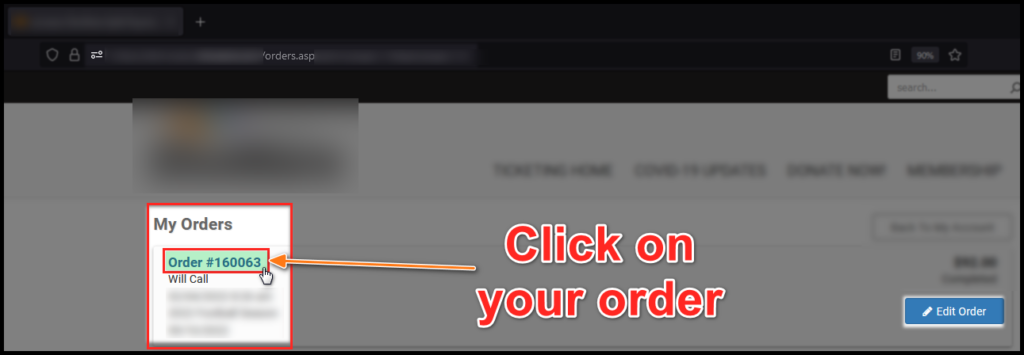
And the injection is successful:
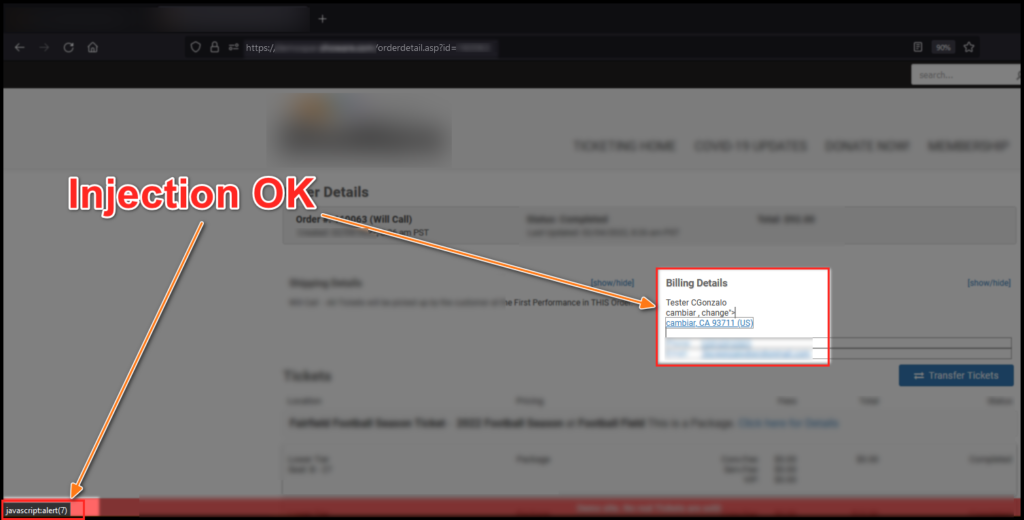
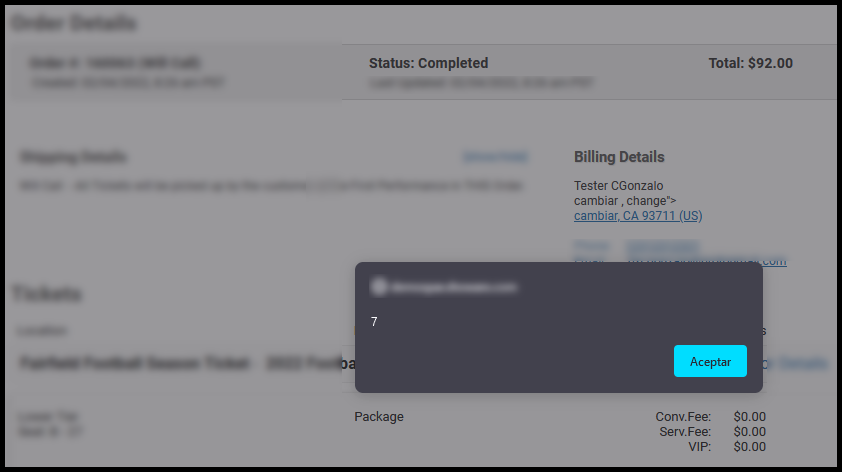
To demonstrate greater impact, it’s always advisable to attempt something more, for example, capturing user credentials by bypassing CSP (not covered in this article). Well, I began testing with the not-so-well-known <script> tag (note the sarcasm), which was initially blocked. However, after searching for the appropriate special characters, using the techniques we’ve discussed here, and breaking the syntax, I was able to achieve it:
change"><script/x>alert(document.domain)</script/x>
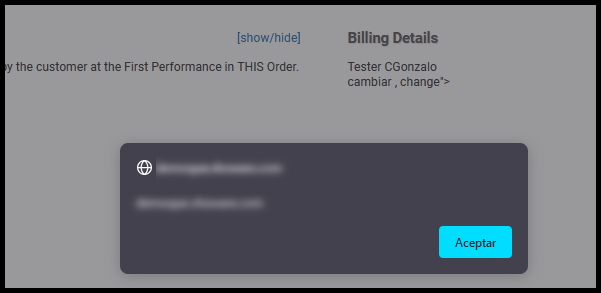
The server responds correctly without detecting the attack. Upon clicking View Order Details the correct injection can be seen:
To capture the credentials and develop the necessary Proof of Concept (PoC), I made use of the fetch method, since XMLHttpRequest was blocked and is hardly used anymore:
Lastly, but certainly not least, capturing cookies was only possible if the User-Agent was changed to mobile User-Agent, such as Android or iOS (which reminds me of a good article on how to detect endpoints that are not visible at first glance) at the time of sending the request:


To ensure it truly worked, I conducted tests with one of the managers of the private program, and the following screenshot belongs to their mobile device:
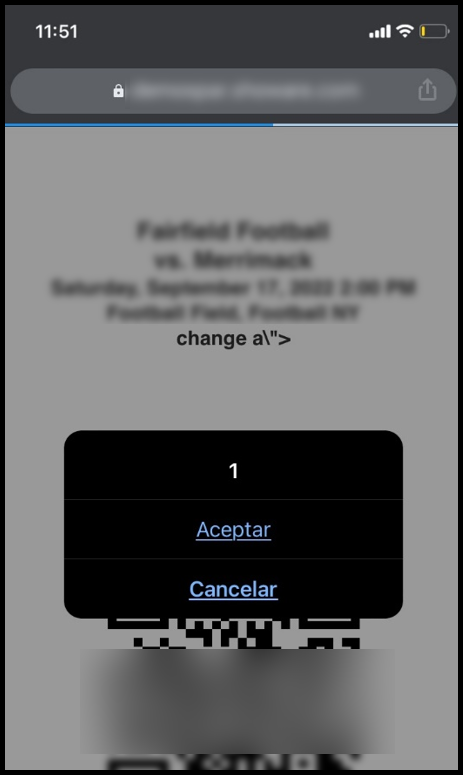
I found it interesting to share this discovery, as I hadn’t previously come across a scenario where the WAF considered the User-Agent header (possibly due to a blacklist in this case) to allow or disallow certain behavior.
Before concluding, I would like to recommend an excellent article by my colleague and friend, Jorge Lajara, which complements this post.
Take care.